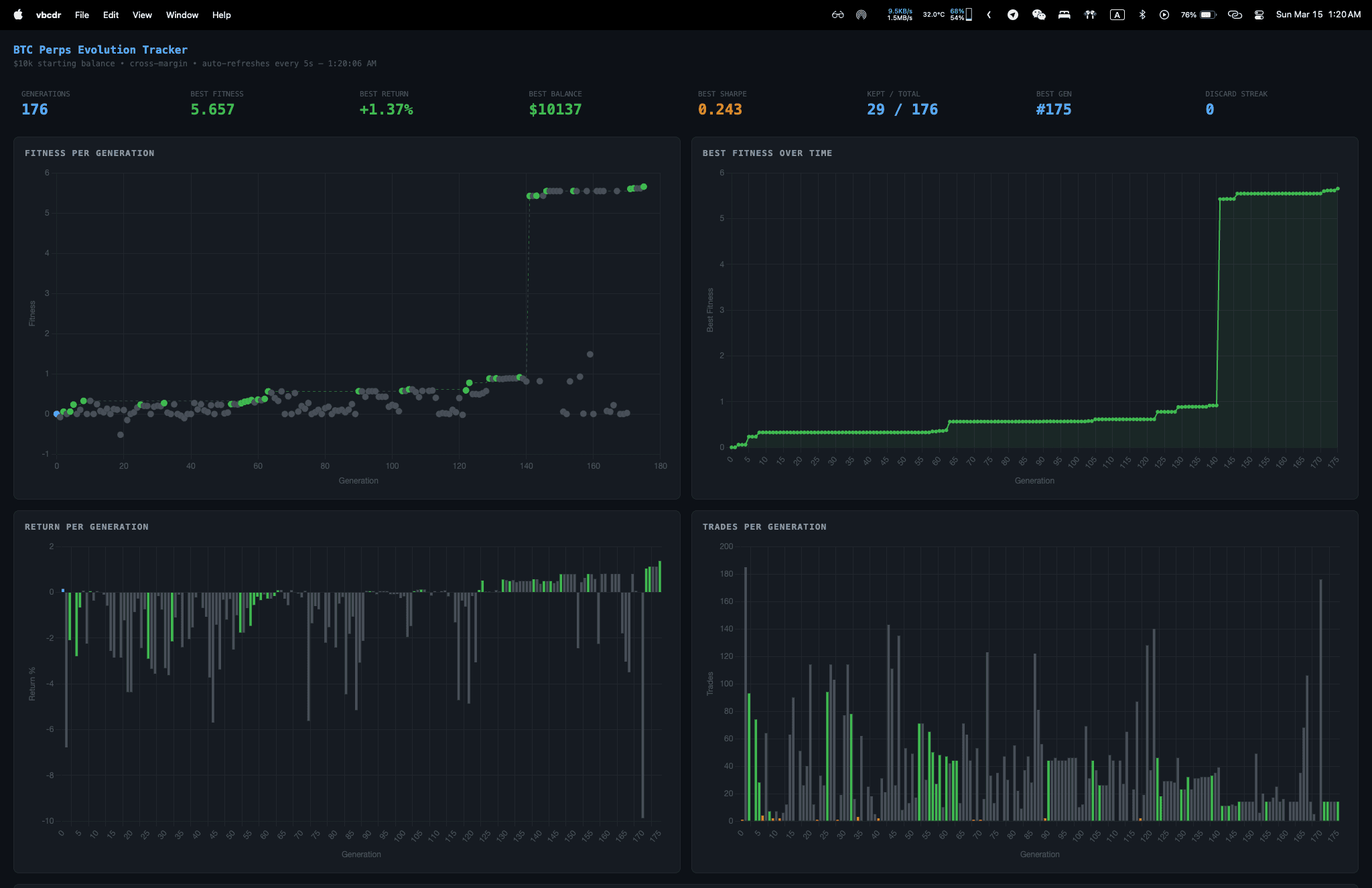
Je hebt waarschijnlijk wel van llms.txt gehoord als je de AI-wereld een beetje volgt. Zie het als robots.txt maar dan voor LLM's.
Het probleem dat het oplost
LLM's hebben een fundamenteel probleem: contextvensters. Ze kunnen maar een beperkte hoeveelheid tekst tegelijk verwerken. Wanneer een AI je website probeert te begrijpen, loopt het tegen een paar problemen aan:
- HTML is rommelig — navigatie, advertenties, scripts en daadwerkelijke content door elkaar
- Websites zijn enorm — de meeste sites hebben honderden pagina's
- Structuur is overal anders — elke site doet het anders
Een complexe website omzetten naar iets dat een LLM daadwerkelijk kan gebruiken is lastig. Daar komt llms.txt om de hoek kijken.
Wat is llms.txt?
Jeremy Howard (medeoprichter van Answer.AI) stelde dit voor in september 2024. Het is in feite een markdown-bestand in de root van je website dat het volgende biedt:
- een kort overzicht van je site
- waar elke sectie over gaat
- links naar de belangrijke content met beschrijvingen
- context die AI helpt begrijpen wat je aanbiedt
Het is een gecureerde index die specifiek voor machines is gebouwd.
Het formaat
Het is gewoon platte markdown. Dit is de basisstructuur:
# Site Name> Brief tagline or description## AboutA paragraph explaining what this site is and who it's for.## Site Structure- Homepage: / - What visitors find here- Documentation: /docs - Technical guides and API references- Blog: /blog - Articles and updates## Key Pages- [Getting Started](/docs/getting-started) - First steps for new users- [API Reference](/docs/api) - Complete API documentation## Contact- Email: hello@example.com- GitHub: github.com/example
Praktijkvoorbeeld
Dit is wat ik voor deze site gebruik:
# Jo Vinkenroye - Web Application Developer> Building ERP systems, SaaS platforms, and modern web applications## AboutSenior developer with 13+ years of experience specializing inReact, Next.js, blockchain development, and AI integration.## Site Structure- Homepage: / - Overview of skills, experience, and projects- Experience: /experience - Detailed work history- Blog: /blog - Technical articles and project write-ups## Blog Posts- Building a Tamagotchi on Garmin: /blog/garmigotchi- Ad-Forge - AI-Powered Ad Generation: /blog/ad-forge
Moet je er eentje toevoegen?
Oké, de eerlijke waarheid: geen enkel groot AI-bedrijf heeft officieel gezegd dat ze llms.txt gebruiken bij het crawlen. Het is een voorgestelde standaard, geen geadopteerde.
Maar de adoptie groeit. Anthropic, Cloudflare, Vercel, Cursor — ze hebben het allemaal geïmplementeerd. Mintlify rolde het eind 2024 uit voor al hun gehoste documentatie.
Voeg er een toe als:
- je documentatie of technische content hebt
- je vroeg wilt zijn met iets dat potentieel belangrijk wordt
- je bouwt voor AI-native vindbaarheid
- het kost 10 minuten en niets
Sla het over als:
- je site vooral visuele content is
- je wacht op officiële adoptie
Implementatie in Next.js
Als je Next.js gebruikt met de App Router kun je een dynamische route aanmaken:
// app/llms.txt/route.tsExport async function GET() {const content = `# Your Site Name> Your tagline here## AboutYour description...## Key Pages- Homepage: / - Main landing page- Blog: /blog - Articles and guides`;return new Response(content, {headers: {'Content-Type': 'text/plain; charset=utf-8',},});}
Voor dynamische content zoals blogposts kun je het programmatisch genereren:
// app/llms.txt/route.tsImport { getAllPosts } from '@/lib/blog';Export async function GET() {const posts = getAllPosts();const blogSection = posts.map(post => `- ${post.title}: /blog/${post.slug}`).join('\n');const content = `# My Site## Blog Posts${blogSection}`;return new Response(content, {headers: { 'Content-Type': 'text/plain; charset=utf-8' },});}
Tools en bronnen
Een paar tools kunnen je hierbij helpen:
- llms_txt2ctx — CLI voor het parsen en genereren van context
- vitepress-plugin-llms — VitePress-integratie
- docusaurus-plugin-llms — Docusaurus-integratie
- GitBook — genereert automatisch voor alle gehoste documentatie
Het grotere plaatje
Of llms.txt nu een universele standaard wordt of niet, het probleem dat het oplost gaat niet weg. AI-modellen zullen gestructureerde toegang tot webcontent nodig blijven hebben.
Door het nu te implementeren:
- Maak je je content toegankelijker voor huidige AI-tools
- Bereid je je voor op mogelijke toekomstige adoptie
- Denk je na over content vanuit een AI-first perspectief
Dat laatste is misschien het meest waardevol. Naarmate AI een primaire manier wordt waarop mensen content ontdekken, wordt machineherkenning net zo belangrijk als menselijke leesbaarheid.
Conclusie
llms.txt is simpel en kost weinig moeite, maar kan zich uitbetalen naarmate AI-native vindbaarheid groeit. Het kost minuten om te implementeren en signaleert dat je site klaar is voor het AI-first web.
Bekijk de officiële specificatie voor meer details, of kijk hoe Anthropic en Vercel het hebben aangepakt.
Stay Updated
Get notified about new posts on automation, productivity tips, indie hacking, and web3.
No spam, ever. Unsubscribe anytime.