我运营着 globalpetsitter.com,一个连接全球宠物主人和宠物保姆的平台。跟所有创业项目一样,我需要宣传内容,特别是社交媒体上的视频广告。问题是哪怕做一个简单的 30 秒广告都要花很久
问题所在
每次我想做视频广告,流程大概是这样的:
- 写脚本或分镜
- 为每个场景找或者做图片
- 生成或录制配音
- 把图片转成带动效的视频片段
- 音视频同步
- 在剪映(CapCut)里把所有东西剪在一起
每一步都要用不同的工具、不同的账号登录、大量的上下文切换。一个 6 个场景的广告轻松花掉好几个小时。不满意结果?从头来过
Ad Forge
我做了 Ad Forge,把以上所有步骤压缩成一条流水线。用纯文本描述你的广告,让 AI 来干活
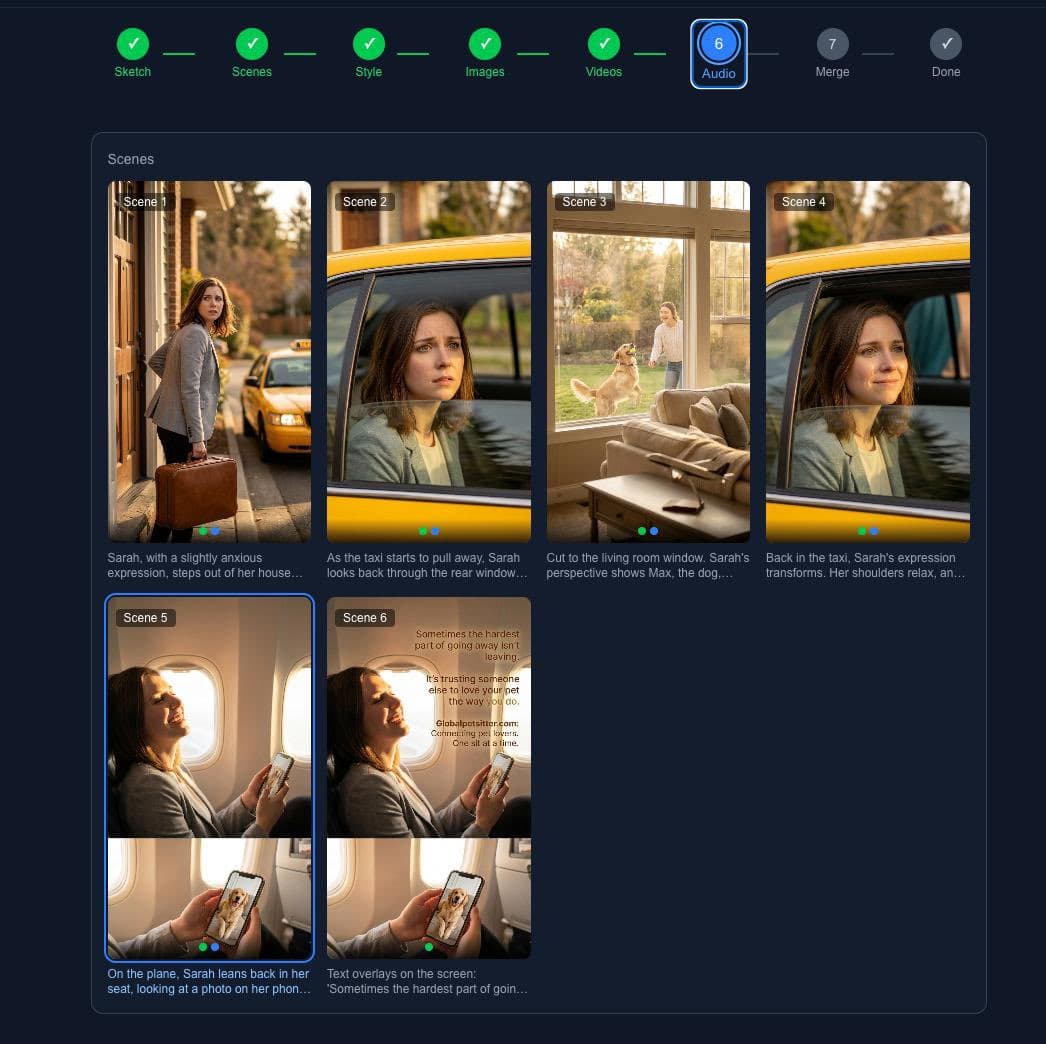
看看输出效果:
工作原理
分为 7 个阶段:
1. 草案(Sketch) - 描述你的广告概念、目标受众、风格调性、时长。比如 GlobalPetSitter 的广告我写的大概是「一个女人要出远门,担心自己的宠物,然后知道宠物有人照顾后感到安心」
2. 分镜(Scenes) - Gemini 把你的草案拆分成单独的场景,包含描述、场景设定、氛围、建议时长。它会自动构建叙事弧线
3. 风格(Style) - AI 生成风格指南。色彩方案、光线、视觉氛围、角色描述、场景细节。确保所有画面视觉上保持一致
4. 图片(Images) - Fal.ai 为每个场景生成图片。系统会使用前面场景的参考图和角色肖像来保持一致性。这是最难搞的部分
5. 视频(Videos) - 每张图片变成一个带镜头运动的视频片段(平移、缩放、推拉等)。Fal.ai 的图生视频在这方面做得还不错
6. 音频(Audio) - 有对白的场景会用 TTS(文本转语音)生成配音。你可以给不同角色分配不同的声音
7. 合成(Merge) - 合并视频和音频,可选口型同步。用 FFmpeg 处理
技术栈
- Next.js 16 + React 19 做 UI
- Google Gemini 做脚本生成和场景拆分
- Fal.ai 做图片生成和图生视频
- OpenAI 做部分文本生成
- FFmpeg WebAssembly 在浏览器里做视频处理
一些设计决策
项目持久化 - 所有内容自动保存到 localStorage。关掉浏览器回来继续
参考图片 - 这个至关重要。生成第 3 个场景的时候,你可以引用场景图片、角色肖像、之前的场景。AI 把这些当作风格锚点
阶段式工作流 - 每个阶段产出的结果都可以审核。不满意场景?在继续之前重新生成就好。给你控制权但不会让你被选项淹没
效果
做 GlobalPetSitter 广告原本要花一整天,现在大约 30 分钟的主动操作(加上生成等待时间)。更重要的是我可以快速迭代——尝试不同的调性、换掉场景、重新生成某张图片,不用从头开始
接下来
Ad Forge 还比较粗糙。我想加上:
- 背景音乐选择
- 更多镜头运动选项
- 直接导出社交媒体格式(9:16 给 TikTok/Reels,16:9 给 YouTube)
- 常见广告格式的模板
目前它解决了我的问题:不用花大量时间就能给 GlobalPetSitter 做视频广告。有时候这就够了 :)
Stay Updated
Get notified about new posts on automation, productivity tips, indie hacking, and web3.
No spam, ever. Unsubscribe anytime.