
Tu as un agent IA qui tourne quelque part — peut-etre un LLM local, peut-etre un agent avec de la memoire et des outils, peut-etre juste un wrapper OpenAI. Tu lui parles en tapant. Dans un navigateur. Comme un sauvage.
Et si tu pouvais juste dire "Siri, parle a mon agent" en te baladant avec des AirPods ? Telephone verrouille, mains libres, conversation complete ?
Il s'avere que ca prend environ 50 lignes de JavaScript et 45 minutes de ton temps.
l'architecture
Cinq composants. L'un est un Siri Shortcut. L'autre fait 50 lignes de code. Le reste, tu l'as probablement deja.
- Siri Shortcut — reconnaissance vocale sur ton iPhone
- Voice API — petit serveur Node.js qui relie tout ensemble
- Ton agent IA — n'importe quel endpoint OpenAI-compatible chat completions
- Edge TTS — synthese vocale gratuite (324 voix, zero cout)
- Cloudflare Tunnel — exposition HTTPS gratuite pour ton serveur
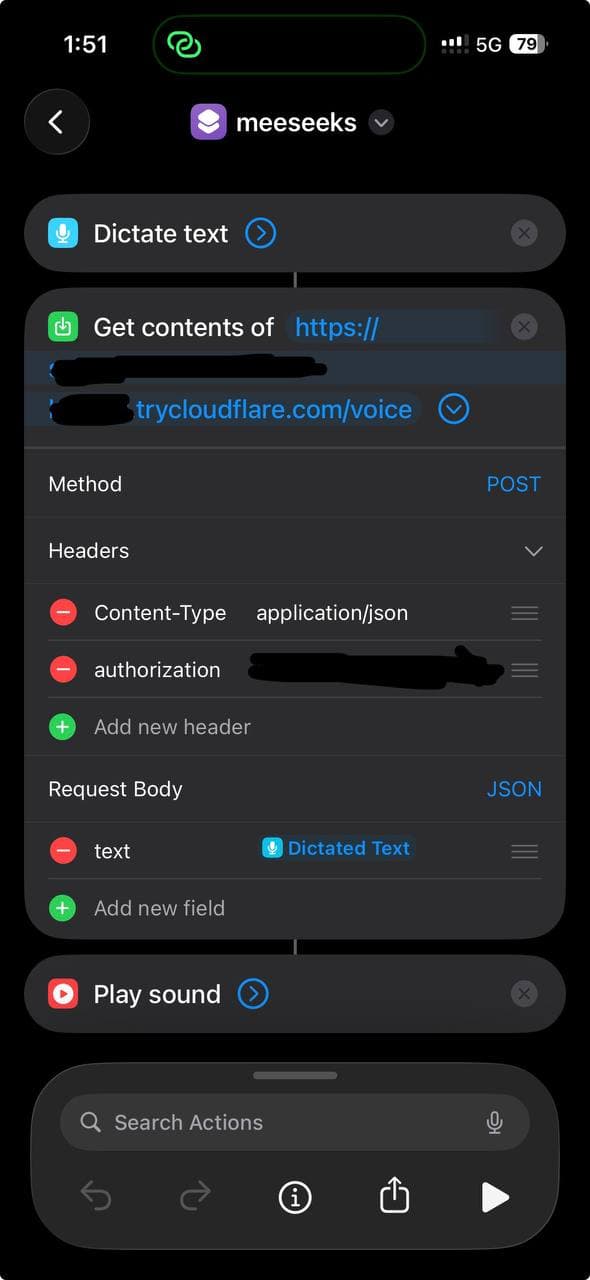
1. le siri shortcut
Cree un nouveau Shortcut sur ton iPhone avec trois actions :
- Dictate Text — Siri ecoute et transcrit
- Get Contents of URL — POST le texte vers ton voice API
- Play Sound — joue la reponse MP3
Configure l'action URL :
- Methode : POST
- Headers :
Content-Type: application/jsonAuthorization: Bearer your-secret-token
- Body (JSON) :
text: Dictated Text (la variable magique de l'etape 1)
Nomme-le comme tu veux. "Assistant", "Jarvis", "Ordinateur" — puis declenche-le avec "Siri, [nom]".
Voici a quoi ca ressemble :
Fonctionne avec le telephone verrouille. Fonctionne avec les AirPods. Fonctionne en promenent le chien.
2. le voice API
Voici le serveur complet :
const express = require('express');const { execSync } = require('child_process');const fs = require('fs');const app = express();app.use(express.json());const AUTH_TOKEN = process.env.AUTH_TOKEN || 'your-secret-token';const AI_URL = process.env.AI_URL || 'https://api.openai.com/v1/chat/completions';const AI_TOKEN = process.env.AI_TOKEN || 'your-ai-api-key';const AI_MODEL = process.env.AI_MODEL || 'gpt-4o';const TTS_VOICE = process.env.TTS_VOICE || 'en-US-AndrewNeural';app.post('/voice', async (req, res) => {try {const token = (req.headers['authorization'] || '').replace('Bearer ', '').trim();if (token !== AUTH_TOKEN)return res.status(401).json({ error: 'unauthorized' });const text = req.body?.text;if (!text)return res.status(400).json({ error: 'no text' });// 1. Ask your AI agentconst r = await fetch(AI_URL, {method: 'POST',headers: {'Content-Type': 'application/json','Authorization': 'Bearer ' + AI_TOKEN,},body: JSON.stringify({model: AI_MODEL,max_tokens: 300,user: 'voice-user', // persistent session across callsmessages: [{role: 'system',content: 'User is speaking via voice. Keep responses '+ 'SHORT (2-3 sentences). Spoken aloud. '+ 'No markdown, bullets, code, or URLs.'},{ role: 'user', content: text }],}),});const data = await r.json();let reply = data.choices?.[0]?.message?.content || 'No response.';// 2. Convert to speech (free!)const tmp = '/tmp/voice-' + Date.now() + '.mp3';execSync(`edge-tts --voice ${TTS_VOICE} ` +`--text '${reply.replace(/'/g, "'\\''")}' ` +`--write-media ${tmp} 2>/dev/null`,{ timeout: 15000 });const audio = fs.readFileSync(tmp);fs.unlinkSync(tmp);res.set('Content-Type', 'audio/mpeg');res.send(audio);} catch (err) {if (!res.headersSent)res.status(500).json({ error: err.message });}});app.get('/health', (req, res) => res.json({ ok: true }));app.listen(3456, () => console.log('Voice API on :3456'));
Installe les dependances et lance :
npm init -ynpm install expresspip install edge-ttsnode server.js
C'est tout. L'API recoit du texte, interroge ton agent IA, convertit la reponse en parole et renvoie un MP3.
3. ton agent IA
Le voice API appelle n'importe quel endpoint OpenAI-compatible /v1/chat/completions. Ca veut dire que ca fonctionne avec :
- OpenAI directement (
https://api.openai.com/v1/chat/completions) - LLM locaux via Ollama, LM Studio, vLLM, etc. (
http://localhost:11434/v1/chat/completions) - Agents IA comme OpenClaw, LangServe, ou tout ce qui expose le format OpenAI
- Anthropic via un proxy ou un wrapper compatible
Si ton agent IA a de la memoire, des outils et des sessions persistantes — tu as maintenant une interface vocale vers un agent complet, pas juste un chatbot. Le champ user dans le corps de la requete te donne la persistance de session directement — ton agent se souvient des conversations vocales precedentes.
Configure les variables d'environnement :
export AI_URL="http://localhost:11434/v1/chat/completions" # ollama exampleexport AI_TOKEN="not-needed-for-local"export AI_MODEL="llama3"
l'astuce du system prompt
La cle pour que ca fonctionne bien, c'est le system prompt :
User is speaking via voice. Keep responses SHORT (2-3 sentences).Spoken aloud. No markdown, bullets, code, or URLs.
Sans ca, ton agent IA va repondre avec de la mise en forme, des blocs de code, des listes a puces — tout ca sonne horriblement en TTS. Ce prompt force le mode conversationnel tout en gardant toutes les capacites intactes.
4. Edge TTS — la voix gratuite
Edge TTS est le moteur de synthese vocale de Microsoft tire de la fonction "Lecture a voix haute" du navigateur Edge. C'est gratuit, il y a 324 voix, et la qualite est vraiment bonne.
pip install edge-tts# list all voicesedge-tts --list-voices# generate speechedge-tts --voice en-US-AndrewNeural \--text "Hello from your AI assistant" \--write-media output.mp3
Quelques bonnes voix a essayer :
en-US-AndrewNeural— naturel, conversationnel (mon choix par defaut)en-US-JennyNeural— clair, professionnelen-GB-SoniaNeural— britannique, chaleureuxzh-CN-XiaoxiaoNeural— chinois mandarinde-DE-ConradNeural— allemand
Gratuit. Rapide. Pas de cles API. Pas de quotas. Compare a OpenAI TTS a 15$/million de caracteres, c'est une evidence pour un projet personnel.
5. Cloudflare Tunnel
Les Siri Shortcuts ont besoin de HTTPS. Si ton serveur ne l'a pas, les Cloudflare Quick Tunnels te donnent une URL publique en une seule commande :
# installcurl -L https://github.com/cloudflare/cloudflared/releases/latest/download/cloudflared-linux-amd64 \-o /usr/local/bin/cloudflaredchmod +x /usr/local/bin/cloudflared# runcloudflared tunnel --url http://localhost:3456
Tu obtiens une URL comme https://random-words.trycloudflare.com. Mets-la dans ton Siri Shortcut comme https://random-words.trycloudflare.com/voice.
Les quick tunnels sont gratuits mais ephemeres — l'URL change quand tu redemarres. Pour une configuration permanente, utilise un named tunnel avec ton propre domaine.
cout total
Tout sauf l'IA elle-meme est gratuit :
- Siri Shortcut — gratuit
- Voice API — gratuit (Node.js)
- Edge TTS — gratuit (324 voix, pas de cle API)
- Cloudflare Tunnel — gratuit
- Ton agent IA — ca depend (LLM local = gratuit, OpenAI = seulement le cout des tokens)
Pas de cout TTS. Pas de cout de reconnaissance vocale. Siri gere la transcription, Edge TTS gere la synthese. Tu ne paies que les tokens de chat completion — si tant est que tu paies.
latence
Typiquement de bout en bout : 3-5 secondes entre la fin de ta phrase et le debut de la reponse.
- Transcription Siri : ~500ms
- Reseau vers le serveur : ~200ms
- Reponse IA : ~1-2s (varie selon le modele)
- Generation Edge TTS : ~500ms
- Reseau retour + debut audio : ~200ms
Assez rapide pour donner l'impression d'une conversation. Pas assez rapide pour se couper la parole. C'est probablement tres bien comme ca.
OpenClaw quickstart
Si tu fais tourner OpenClaw, voici la configuration prete a l'emploi. OpenClaw expose un endpoint OpenAI-compatible sur ta gateway, donc le voice API parle directement a ton agent — avec toute la memoire, les outils et le contexte de session.
1. Active l'endpoint chat completions :
openclaw config patch '{"http": {"endpoints": {"chatCompletions": { "enabled": true }}}}'
2. Recupere ton token gateway :
cat ~/.openclaw/gateway.json | jq -r '.auth.bearerTokens[0]'
3. Configure tes variables d'environnement :
export AI_URL="http://127.0.0.1:18789/v1/chat/completions"export AI_TOKEN="your-gateway-bearer-token"export AI_MODEL="openclaw:main"export AUTH_TOKEN="pick-a-secret-for-siri"export TTS_VOICE="en-US-AndrewNeural"
4. Lance le serveur vocal + tunnel :
node server.js &cloudflared tunnel --url http://localhost:3456
5. Cree le Siri Shortcut avec l'URL du tunnel + ton token d'authentification.
C'est tout. Tu parles maintenant a ton agent OpenClaw complet via les AirPods — le meme agent qui gere tes messages, emails, fichiers et outils. Pas un wrapper vocal au rabais.
pro tip : bouton d'action
Si tu as un iPhone 15 Pro ou plus recent, saute completement l'activation vocale. Associe ton bouton d'action au Siri Shortcut :
Reglages → Bouton d'action → Raccourci → selectionne ton raccourci vocal
Un appui. Dicte. Termine. Pas besoin du prefixe "Siri, ...". C'est la facon la plus rapide de declencher tout ca.
aller plus loin
Quelques ameliorations si tu veux pousser le concept :
- TTS en streaming — decoupe la sortie IA et genere le TTS incrementalement pour reduire la latence percue de moitie
- Named tunnel + domaine perso — pour que l'URL de ton Siri Shortcut ne casse pas au redemarrage
- Voix multiples — detecte la langue dans la reponse et change de voix TTS automatiquement (Edge TTS supporte 40+ langues)
- Mot declencheur sans Siri — fais tourner un detecteur de mot declencheur sur un Raspberry Pi pour une ecoute permanente
le tout en resume
"Siri, assistant"→ iPhone transcrit la parole→ POST vers ton serveur→ Le serveur interroge ton agent IA→ L'agent repond (2-3 phrases)→ Edge TTS convertit en MP3→ MP3 joue dans les AirPods← 3-5 secondes au total
50 lignes de JavaScript. TTS gratuit. Fonctionne avec n'importe quel backend IA. Mains libres, telephone verrouille, AirPods dans les oreilles.
Parfois les meilleurs hacks sont les plus simples.
Stay Updated
Get notified about new posts on automation, productivity tips, indie hacking, and web3.
No spam, ever. Unsubscribe anytime.


