
Tienes un agente IA corriendo en alguna parte — quiza un LLM local, quiza un agente con memoria y herramientas, quiza solo un wrapper de OpenAI. Le hablas escribiendo. En un navegador. Como un cavernicola.
Y si pudieras simplemente decir "Siri, habla con mi agente" mientras caminas con los AirPods puestos? Telefono bloqueado, manos libres, conversacion completa?
Resulta que son unas 50 lineas de JavaScript y 45 minutos de tu tiempo.
la arquitectura
Cinco piezas. Una es un Siri Shortcut. Otra son 50 lineas de codigo. El resto probablemente ya lo tienes.
- Siri Shortcut — reconocimiento de voz en tu iPhone
- Voice API — pequeno servidor Node.js que une todo
- Tu agente IA — cualquier endpoint OpenAI-compatible de chat completions
- Edge TTS — texto a voz gratuito (324 voces, cero coste)
- Cloudflare Tunnel — exposicion HTTPS gratuita para tu servidor
1. el siri shortcut
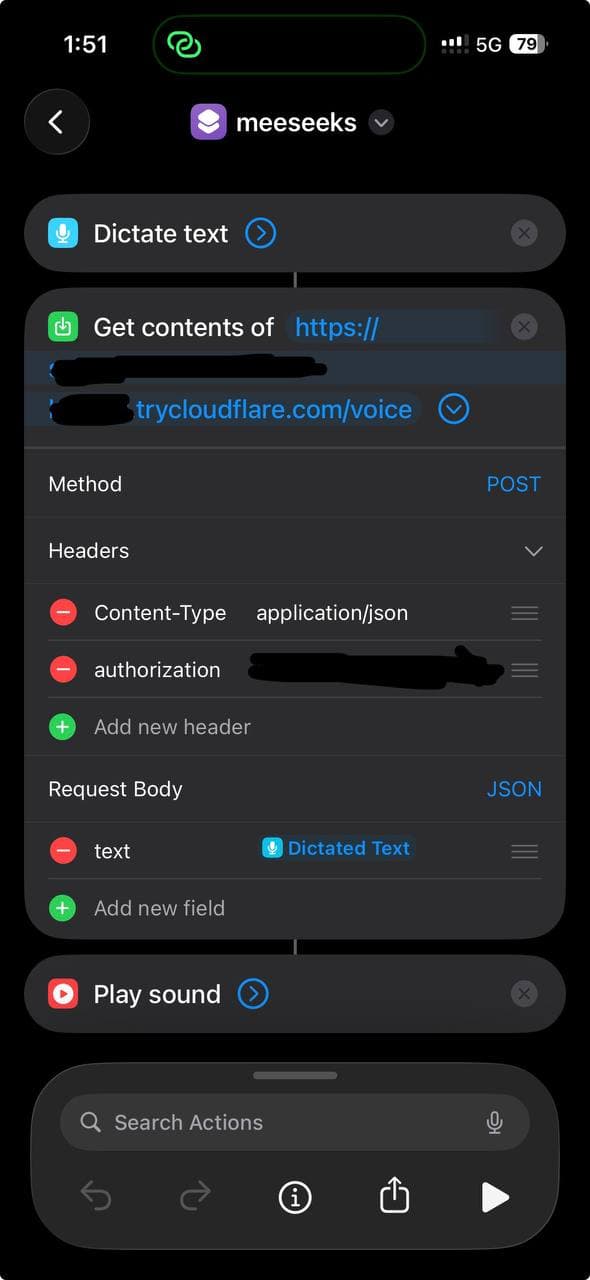
Crea un nuevo Shortcut en tu iPhone con tres acciones:
- Dictate Text — Siri escucha y transcribe
- Get Contents of URL — POST del texto a tu voice API
- Play Sound — reproduce la respuesta en MP3
Configura la accion URL:
- Metodo: POST
- Headers:
Content-Type: application/jsonAuthorization: Bearer your-secret-token
- Body (JSON):
text: Dictated Text (la variable magica del paso 1)
Ponle el nombre que quieras. "Asistente", "Jarvis", "Computadora" — y activalo con "Siri, [nombre]".
Asi es como se ve:
Funciona con el telefono bloqueado. Funciona con AirPods. Funciona mientras paseas al perro.
2. el voice API
Este es el servidor completo:
const express = require('express');const { execSync } = require('child_process');const fs = require('fs');const app = express();app.use(express.json());const AUTH_TOKEN = process.env.AUTH_TOKEN || 'your-secret-token';const AI_URL = process.env.AI_URL || 'https://api.openai.com/v1/chat/completions';const AI_TOKEN = process.env.AI_TOKEN || 'your-ai-api-key';const AI_MODEL = process.env.AI_MODEL || 'gpt-4o';const TTS_VOICE = process.env.TTS_VOICE || 'en-US-AndrewNeural';app.post('/voice', async (req, res) => {try {const token = (req.headers['authorization'] || '').replace('Bearer ', '').trim();if (token !== AUTH_TOKEN)return res.status(401).json({ error: 'unauthorized' });const text = req.body?.text;if (!text)return res.status(400).json({ error: 'no text' });// 1. Ask your AI agentconst r = await fetch(AI_URL, {method: 'POST',headers: {'Content-Type': 'application/json','Authorization': 'Bearer ' + AI_TOKEN,},body: JSON.stringify({model: AI_MODEL,max_tokens: 300,user: 'voice-user', // persistent session across callsmessages: [{role: 'system',content: 'User is speaking via voice. Keep responses '+ 'SHORT (2-3 sentences). Spoken aloud. '+ 'No markdown, bullets, code, or URLs.'},{ role: 'user', content: text }],}),});const data = await r.json();let reply = data.choices?.[0]?.message?.content || 'No response.';// 2. Convert to speech (free!)const tmp = '/tmp/voice-' + Date.now() + '.mp3';execSync(`edge-tts --voice ${TTS_VOICE} ` +`--text '${reply.replace(/'/g, "'\\''")}' ` +`--write-media ${tmp} 2>/dev/null`,{ timeout: 15000 });const audio = fs.readFileSync(tmp);fs.unlinkSync(tmp);res.set('Content-Type', 'audio/mpeg');res.send(audio);} catch (err) {if (!res.headersSent)res.status(500).json({ error: err.message });}});app.get('/health', (req, res) => res.json({ ok: true }));app.listen(3456, () => console.log('Voice API on :3456'));
Instala las dependencias y ejecuta:
npm init -ynpm install expresspip install edge-ttsnode server.js
Eso es todo. La API recibe texto, le pregunta a tu agente IA, convierte la respuesta a voz y devuelve un MP3.
3. tu agente IA
El voice API llama a cualquier endpoint OpenAI-compatible /v1/chat/completions. Eso significa que funciona con:
- OpenAI directamente (
https://api.openai.com/v1/chat/completions) - LLM locales via Ollama, LM Studio, vLLM, etc. (
http://localhost:11434/v1/chat/completions) - Agentes IA como OpenClaw, LangServe, o cualquier cosa que exponga el formato OpenAI
- Anthropic via un proxy o wrapper compatible
Si tu agente IA tiene memoria, herramientas y sesiones persistentes — ahora tienes una interfaz de voz hacia un agente completo, no solo un chatbot. El campo user en el cuerpo de la peticion te da persistencia de sesion de serie — tu agente recuerda conversaciones de voz anteriores.
Configura las variables de entorno:
export AI_URL="http://localhost:11434/v1/chat/completions" # ollama exampleexport AI_TOKEN="not-needed-for-local"export AI_MODEL="llama3"
el truco del system prompt
La clave para que esto funcione bien es el system prompt:
User is speaking via voice. Keep responses SHORT (2-3 sentences).Spoken aloud. No markdown, bullets, code, or URLs.
Sin esto, tu agente IA respondera con formato, bloques de codigo, listas con vinetas — todo eso suena terrible por TTS. Este prompt fuerza el modo conversacional manteniendo todas las capacidades intactas.
4. Edge TTS — la voz gratuita
Edge TTS es el motor de texto a voz de Microsoft sacado de la funcion "Leer en voz alta" del navegador Edge. Es gratuito, tiene 324 voces y la calidad es genuinamente buena.
pip install edge-tts# list all voicesedge-tts --list-voices# generate speechedge-tts --voice en-US-AndrewNeural \--text "Hello from your AI assistant" \--write-media output.mp3
Algunas buenas voces para probar:
en-US-AndrewNeural— natural, conversacional (mi opcion por defecto)en-US-JennyNeural— clara, profesionalen-GB-SoniaNeural— britanica, calidazh-CN-XiaoxiaoNeural— chino mandarinde-DE-ConradNeural— aleman
Gratuito. Rapido. Sin claves API. Sin cuotas. Comparado con OpenAI TTS a $15/millon de caracteres, es una decision obvia para un proyecto personal.
5. Cloudflare Tunnel
Los Siri Shortcuts necesitan HTTPS. Si tu servidor no lo tiene, los Cloudflare Quick Tunnels te dan una URL publica con un solo comando:
# installcurl -L https://github.com/cloudflare/cloudflared/releases/latest/download/cloudflared-linux-amd64 \-o /usr/local/bin/cloudflaredchmod +x /usr/local/bin/cloudflared# runcloudflared tunnel --url http://localhost:3456
Obtendras una URL como https://random-words.trycloudflare.com. Ponla en tu Siri Shortcut como https://random-words.trycloudflare.com/voice.
Los quick tunnels son gratuitos pero efimeros — la URL cambia cuando reinicias. Para una configuracion permanente, usa un named tunnel con tu propio dominio.
coste total
Todo excepto la IA en si es gratuito:
- Siri Shortcut — gratuito
- Voice API — gratuito (Node.js)
- Edge TTS — gratuito (324 voces, sin clave API)
- Cloudflare Tunnel — gratuito
- Tu agente IA — depende (LLM local = gratuito, OpenAI = solo coste de tokens)
Sin costes de TTS. Sin costes de reconocimiento de voz. Siri se encarga de la transcripcion, Edge TTS se encarga de la sintesis. Solo pagas por los tokens de chat completion — si es que pagas algo.
latencia
Tipico de extremo a extremo: 3-5 segundos desde que terminas tu frase hasta que oyes la respuesta.
- Transcripcion Siri: ~500ms
- Red hacia el servidor: ~200ms
- Respuesta IA: ~1-2s (varia segun el modelo)
- Generacion Edge TTS: ~500ms
- Red de vuelta + inicio de audio: ~200ms
Suficientemente rapido para sentirse como una conversacion. No lo bastante rapido para interrumpirse mutuamente. Probablemente esta bien asi.
OpenClaw quickstart
Si estas ejecutando OpenClaw, aqui tienes la configuracion lista para copiar y pegar. OpenClaw expone un endpoint OpenAI-compatible en tu gateway, asi que el voice API habla directamente con tu agente — con toda la memoria, herramientas y contexto de sesion.
1. Habilita el endpoint de chat completions:
openclaw config patch '{"http": {"endpoints": {"chatCompletions": { "enabled": true }}}}'
2. Obtén tu token de gateway:
cat ~/.openclaw/gateway.json | jq -r '.auth.bearerTokens[0]'
3. Configura tus variables de entorno:
export AI_URL="http://127.0.0.1:18789/v1/chat/completions"export AI_TOKEN="your-gateway-bearer-token"export AI_MODEL="openclaw:main"export AUTH_TOKEN="pick-a-secret-for-siri"export TTS_VOICE="en-US-AndrewNeural"
4. Ejecuta el servidor de voz + tunnel:
node server.js &cloudflared tunnel --url http://localhost:3456
5. Crea el Siri Shortcut con la URL del tunnel + tu token de autenticacion.
Eso es todo. Ahora estas hablando con tu agente OpenClaw completo a traves de los AirPods — el mismo agente que gestiona tus mensajes, correos, archivos y herramientas. No un wrapper de voz recortado.
pro tip: boton de accion
Si tienes un iPhone 15 Pro o posterior, saltate la activacion por voz completamente. Asigna tu boton de accion al Siri Shortcut:
Ajustes → Boton de accion → Atajo → selecciona tu atajo de voz
Un toque. Dicta. Listo. No necesitas el prefijo "Siri, ...". Es la forma mas rapida de activar esto.
mejoras posibles
Algunas mejoras si quieres ir mas alla:
- TTS en streaming — fragmenta la salida de la IA y genera TTS incrementalmente para reducir la latencia percibida a la mitad
- Named tunnel + dominio propio — para que la URL de tu Siri Shortcut no se rompa al reiniciar
- Multiples voces — detecta el idioma en la respuesta y cambia de voz TTS automaticamente (Edge TTS soporta 40+ idiomas)
- Palabra de activacion sin Siri — ejecuta un detector de palabra de activacion en un Raspberry Pi para escucha permanente
todo en pocas palabras
"Siri, asistente"→ iPhone transcribe la voz→ POST a tu servidor→ El servidor consulta a tu agente IA→ El agente responde (2-3 frases)→ Edge TTS convierte a MP3→ MP3 se reproduce en los AirPods← 3-5 segundos en total
50 lineas de JavaScript. TTS gratuito. Funciona con cualquier backend de IA. Manos libres, telefono bloqueado, AirPods puestos.
A veces los mejores hacks son los mas simples.
Stay Updated
Get notified about new posts on automation, productivity tips, indie hacking, and web3.
No spam, ever. Unsubscribe anytime.


